

![]()
In the high-stakes world of machine learning and large-scale scientific computing, the ability to process massive datasets is often the primary bottleneck. As models grow in complexity, researchers frequently turn to the Fast Fourier Transform (FFT)—a mathematical cornerstone used for signal processing, feature extraction, and model regularization. However, as datasets push into the terabyte range, they often exceed the memory capacity of individual hardware accelerators.
To bridge this gap, Google has announced a significant milestone: the integration of native Distributed Fast Fourier Transform (Distributed FFT) support into TensorFlow v2. By leveraging the power of DTensor, the company is enabling developers to compute Fourier Transforms across distributed systems, effectively overcoming the hardware memory walls that have historically limited deep learning researchers.
The Technical Landscape: Why Distributed FFT Matters
The Fast Fourier Transform is a ubiquitous algorithm. From audio processing to image reconstruction and even in the spectral analysis of neural network layers, it is essential for decomposing signals into their constituent frequencies. In a standard, non-distributed environment, an FFT operation requires the entire dataset to reside within the memory of a single GPU or TPU.
As models scale, this requirement becomes a liability. When an image-like dataset—such as high-resolution medical imaging or large-scale satellite telemetry—grows too large to fit on one card, the research pipeline hits a standstill. Previously, developers were forced to implement bespoke, complex workarounds to partition their data.
With the introduction of native support for Distributed FFT, TensorFlow now allows these heavy computations to be spread across multiple accelerators. This approach utilizes a "Single Program, Multiple Data" (SPMD) architecture, ensuring that the heavy lifting of the FFT is performed in parallel across a distributed mesh of computing units.

A Chronology of Innovation: From Research Papers to Native API
The journey to this release is rooted in a long-term Google Research initiative.
- Pre-2021: The industry relied on fragmented, custom-built libraries. Managing large-scale Fourier transforms on hardware like TPUs required significant engineering overhead, often resulting in proprietary codebases that were difficult to maintain.
- The 2021 Research Milestone: The publication of “Large-Scale Discrete Fourier Transform on TPUs” by researcher Tianjian Lu marked a turning point. The paper demonstrated that high-performance distributed FFTs were not only possible but highly efficient when implemented with specific hardware-aware algorithms.
- Early 2023: Google’s DTensor team began integrating these concepts into the TensorFlow ecosystem. The goal was to move away from external libraries and provide a native, "out-of-the-box" solution.
- September 2023: The official rollout. By incorporating Distributed FFT directly into the DTensor API, Google has standardized the process, allowing researchers to apply it to their existing workflows with minimal code changes.
This progression highlights a clear trend in the machine learning community: the shift from experimental research code to integrated, production-ready framework features.
Supporting Data: Performance, Trade-offs, and Communication Overhead
One of the most critical aspects of the new implementation is its transparency regarding performance. Moving to a distributed model is rarely "free" in terms of computational cycles.
The Shuffle-and-Compute Model
The current TensorFlow implementation utilizes a "shuffle-and-local-FFT" methodology—a standard approach shared by robust libraries like FFTW and PFFT. The process involves:
- Shuffling: Data is redistributed across the network to align with the required processing mesh.
- Local FFT: Each device performs a localized FFT calculation on its subset of the data.
- Communication: The results are synchronized and combined.
Profiling the V100 GPU Experiment
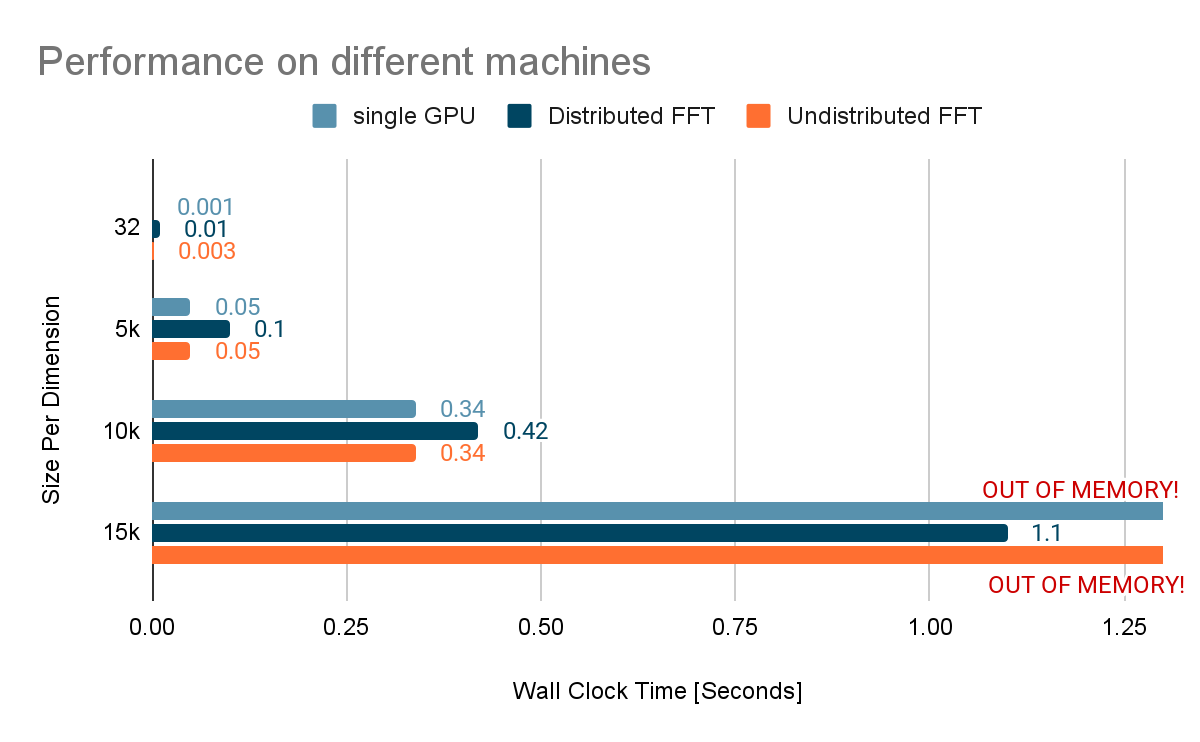
In internal experiments conducted on an 8xV100 GPU system, the performance profile provided a fascinating look at the bottlenecks of distributed computing. When performing a 10K x 10K FFT, the local FFT calculations themselves were incredibly fast—taking only 15ms, or roughly 3.6% of the total wall-clock time.

The remaining time was spent on the ncclAllToAll operation, which manages the communication and data transposition between GPUs. While this might appear as a performance "hit," the trade-off is essential: it allows for the processing of datasets that would otherwise be impossible to handle on a single machine. The distributed implementation successfully transforms a "memory-error-prone" task into a scalable, manageable workflow.
Official Perspective: The Role of DTensor
According to Ruijiao Sun, a lead on the project, the integration was designed to minimize the learning curve for practitioners. "The API interface for distributed FFT is exactly the same as the original FFT in TensorFlow," Sun noted. "Users simply need to pass a sharded tensor to existing operations like tf.signal.fft2d, and DTensor handles the heavy lifting of distributing the workload."
DTensor, the underlying framework, acts as the orchestrator. By utilizing an SPMD expansion, it abstracts the complexity of manual tensor sharding. When a user defines a "mesh"—a grid of available computing devices—DTensor automatically manages how data is sliced, sent across the network, and reassembled. This allows researchers to focus on the mathematics of their models rather than the infrastructure of their distributed clusters.
Implications for the AI and Scientific Community
The implications of this update extend far beyond simple signal processing.
1. Democratization of Large-Scale Science
Previously, only institutions with massive engineering teams could afford to implement custom distributed FFT algorithms. By making this native, Google is enabling smaller research labs to utilize high-resolution data that requires Fourier-based analysis, such as in climate modeling, fluid dynamics, and advanced genomics.
2. Standardized Research Workflows
Because the new API is integrated directly into the tf.signal module, it ensures that research code is portable. A model developed on a single workstation can now be scaled to a multi-node cluster by simply updating the dtensor.Layout configuration. This consistency is vital for the reproducibility of scientific results.
3. Future-Proofing for Larger Models
As Large Language Models (LLMs) and vision models grow in size, the ability to perform complex, non-linear transformations across distributed memory will become increasingly vital. This implementation of Distributed FFT serves as a template for how other complex mathematical operations might be distributed in the future.
Looking Ahead: The Road to Optimization
While the current release provides a robust foundation, the team acknowledges that this is merely the "simplest" version of the algorithm. The community is already looking toward several avenues for optimization:
- Adaptive Communication Patterns: Implementing smarter shuffling algorithms to reduce the time spent in
ncclAllToAll. - Hardware-Specific Tuning: Tailoring the implementation to leverage the specific cache structures of newer-generation GPUs (such as the H100) and TPUs.
- Hybrid Parallelism: Integrating Distributed FFT into pipelines that combine data parallelism with model parallelism to further reduce communication latency.
Conclusion
The arrival of native Distributed FFT in TensorFlow is a testament to the maturation of machine learning infrastructure. By abstracting the complexities of distributed memory management into a familiar API, Google has removed a significant barrier for researchers dealing with massive, high-dimensional datasets.
For those currently struggling with "Out of Memory" errors on large-scale signal processing tasks, the path forward is now clear. By utilizing DTensor, developers can move past the limitations of single-device architecture and harness the full potential of distributed compute clusters. As the TensorFlow Forum continues to collect user feedback, the future of this tool looks promising, offering a scalable path for the next generation of scientific and artificial intelligence research.
